
 捷易科技
捷易科技
GPU与GPU 通过NVLink连接
下图显示了一个包含两个完全NVLink连接的GPU四联体的8-GPU混合立方体网格,四联体之间的NVLink连接以及每个四联体内的GPU直接通过PCIe连接到各自的CPU。通过使用单独的NVLink连接跨越两个四联体之间的间隙,可以减轻对每个CPU的PCIe上行链路的压力,并且避免通过系统内存和跨CPU链接路线路由传输。
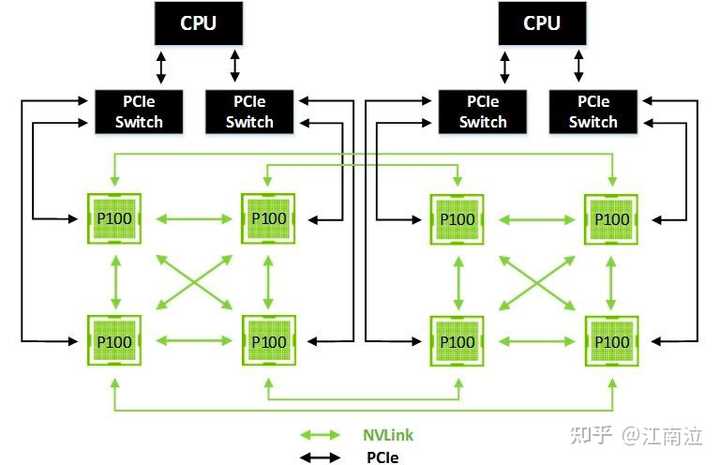
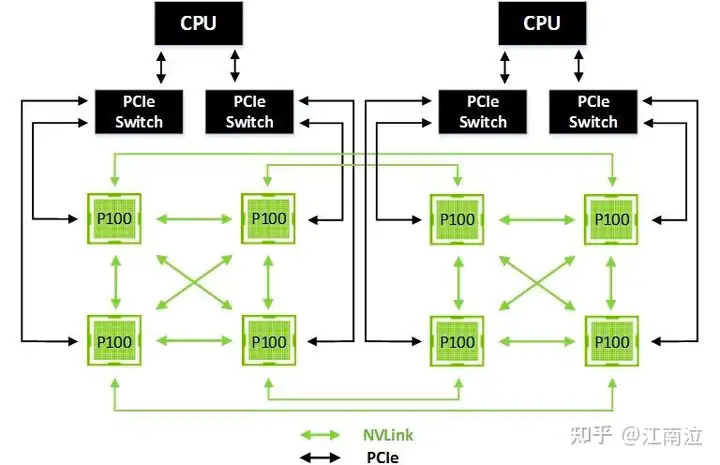
注意,8-GPU混合立方体网格的每一半都可以作为共享内存多处理器运行,而远程节点也可以通过对等DMA共享内存。由于所有GPU到GPU的流量都通过NVLink进行,因此PCIe现在完全可用于连接到NIC(未显示)或用于访问系统内存流量。这种配置通常适用于通用的深度学习应用程序,并已实现在NVIDIA的新DGX-1服务器中。
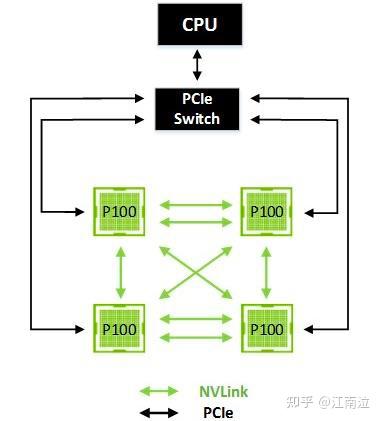
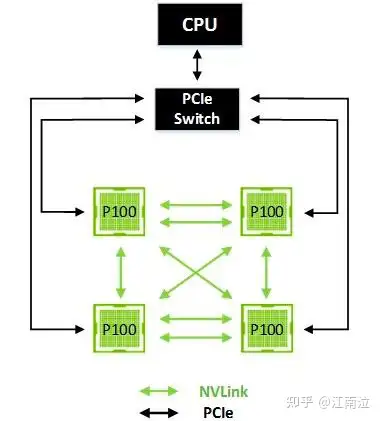
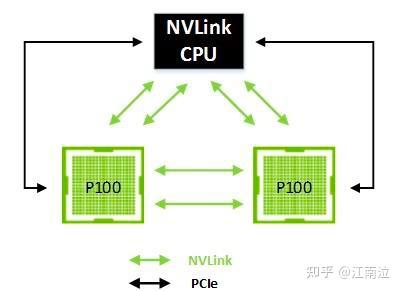
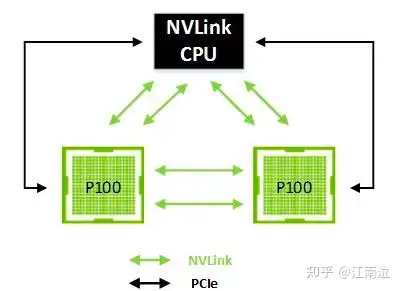
下图展示了一个四个GPU的集群,其中每个GPU都通过单个NVLink连接到其对等方。在这种情况下,对等方可以双向通信,达到40 GB / sec的双向带宽(双重链接的双向带宽为80GB / sec),从而实现GPU之间的强大数据共享。
3.1.2. CPU与GPU通过NVLink连接
虽然NVLink主要集中在将多个NVIDIA Tesla P100加速器连接在一起,但它也可以用作CPU到GPU的互连。例如,Tesla P100加速器可以通过NVIDIA NVLink技术连接到IBM的POWER8。POWER8与NVLink™支持四个NVLink。
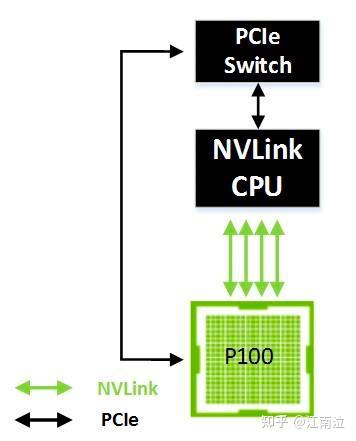
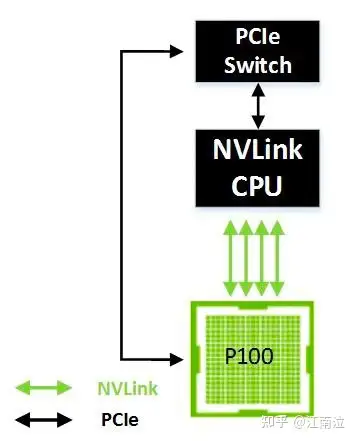
下图显示了一个单GPU连接到启用NVLink的CPU。在这种情况下,GPU可以以高达160 GB / sec的双向带宽访问系统内存,比PCIe提供的带宽高5倍。
下图显示了一个系统,其中每个GPU与CPU之间有两个NVLink。每个GPU上剩余的两个链接用于对等方通信
3.2. NVLink在Tesla P100中的接口
如Tesla P100设计部分所述,NVLink互连在P100加速器上。P100包括两个400针高速连接器。其中一个连接器用于模块上/下的NVLink信号;另一个用于供电、控制信号和PCIe I/O。
Tesla P100加速器可以安装到更大的GPU载体或系统板中。GPU载体可以与其他P100加速器或PCIE控制器建立必要的连接。由于与传统GPU板相比,P100加速器的尺寸更小,因此客户可以轻松构建装有比以往更多GPU的服务器。通过NVLink提供的额外带宽,GPU到GPU的通信不会因PCIe带宽的限制而成为瓶颈,为GPU聚类提供以前不可用的机会。
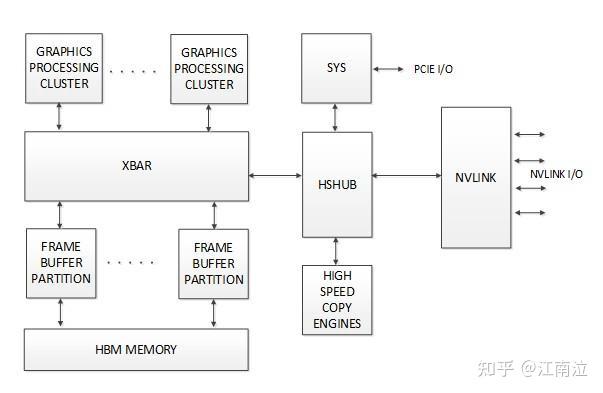
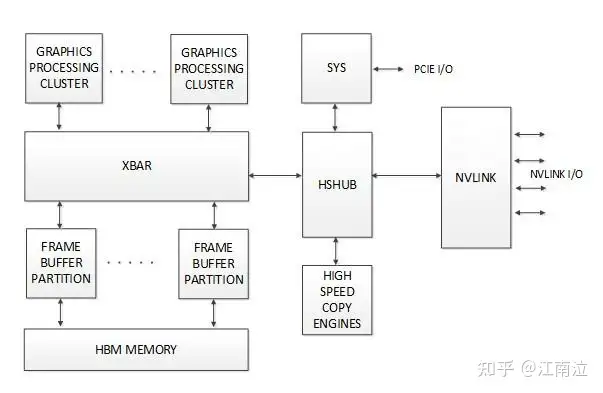
在GPU架构接口层面上,NVLink控制器通过另一个名为High-Speed Hub(HSHUB)的新块与GPU内部通信。HSHUB直接访问GPU宽交叉开关和其他系统元素,例如高速复制引擎(HSCE),可用于以最高NVLink速率将数据移动进入和移出GPU。下图展示了NVLink与HSHUB以及GP100 GPU中的一些高级块之间的关系。
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。本站原创内容未经允许不得转载,或转载时需注明出处:捷易科技 » GPU与GPU 通过NVLink连接

 英伟达A100显卡为什么那么贵?
英伟达A100显卡为什么那么贵? 如何设置英伟达显卡?
如何设置英伟达显卡? a100显卡80g英伟达这个怎么卖?
a100显卡80g英伟达这个怎么卖? 英伟达显卡驱动下载链接 手动安装驱动程序
英伟达显卡驱动下载链接 手动安装驱动程序